#apache
Read more stories on Hashnode
Articles with this tag
Spark Structured Streaming Dynamic Dataset Join I have came across a unique problem, I had a list of valid names in some remote configuration which...
Spark Streaming Misc Spark Streaming's issue with s3/hdfs as stream source With reference to...
If you are a Data Engineer working with the Big Data ecosystem, you need your components to be connected to one other. As Spark is leading the data...
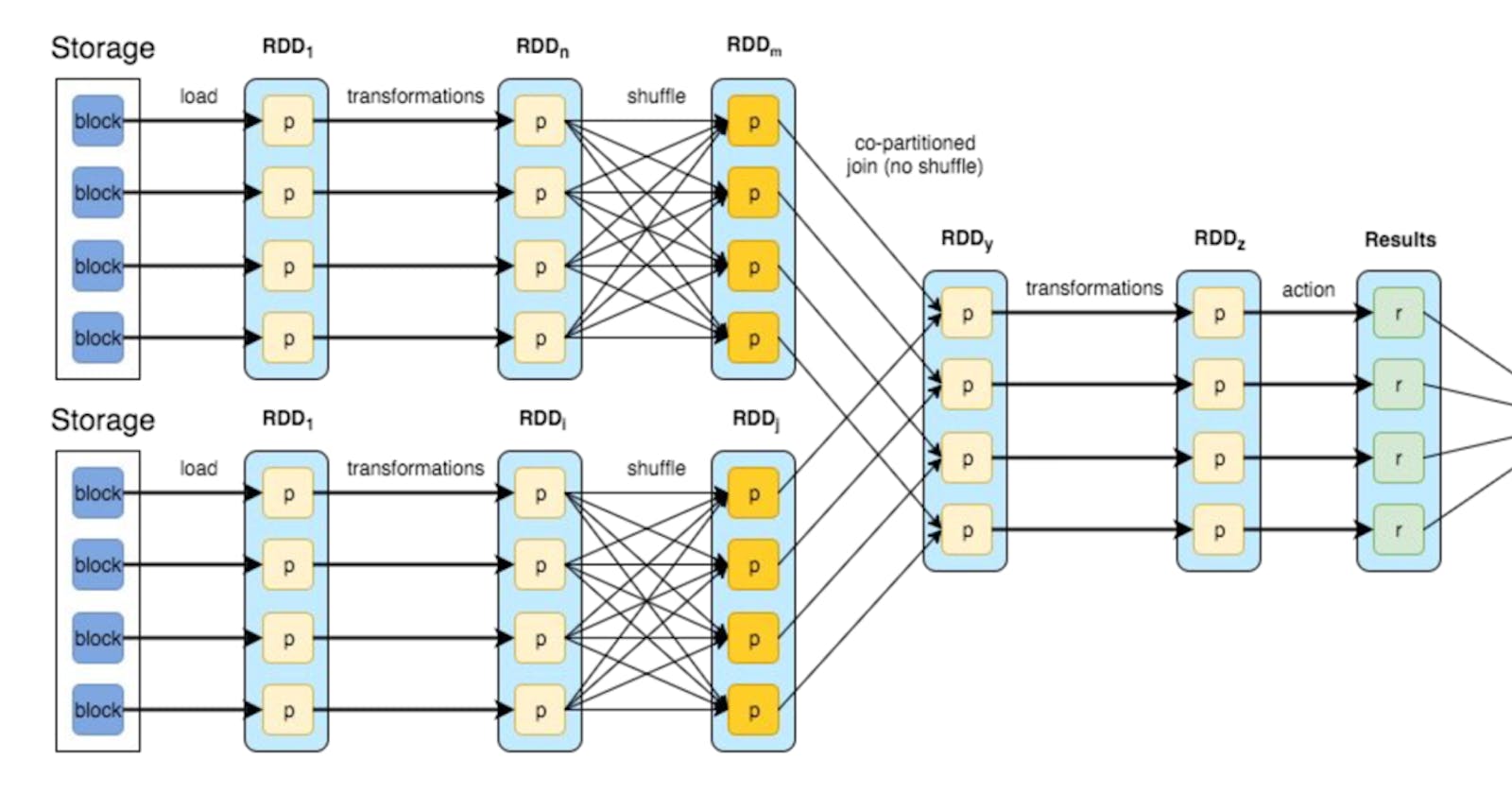
In previous few posts we learned about how scheduling and partitioning can play an important role for achieving better performance from your Apache...
Internal Job Scheduling Inside a given Spark application (SparkContext instance), multiple parallel jobs can run simultaneously if they were...
How partitioning can play a very powerful role in optimising spark jobs · Spark Overview Apache documentations mentions spark framework something like...