




In previous few posts we learned about how scheduling and partitioning can play an important role for achieving better performance from your Apache Spark Application.
Today I will cover some general optimisation techniques and pointers that we can apply to our spark jobs in order to improve performance and drive optimisations.
Persist vs Re-compute
In Spark Persisting/caching is an important technique for reusing a certain computation. Caching can either become your best friend or can become your worst nightmares. Cases where we tend to re-use a certain data caching is really helpful but sometimes the costs of caching is pretty high than recomputing the data from source. Use persist in following types of use-cases,
- Iterative machine learning applications which re-uses same data again and again
- Spark applications which uses single datasource multiple times throughout the execution
- re-compute is expensive than cache
Always remember persisting or caching a dataframe/dataset is not free. It not only takes time to persist data but also end up consuming storage and execution memory depending upon the size of persisted data. Also caching is a lazy transformation which doesn't happen until an action is called on the persisted data.
Spark persist() method takes in a parameter which indicates storage levels such as,
- MEMORY_ONLY
- MEMORY_AND_DISK
- MEMORY_ONLY_SER
- MEMORY_AND_DISK_SER
- DISK_ONLY
- MEMORY_ONLY_2
- MEMORY_AND_DISK_2.
Avoid using params with
..._2with large datasets as that replicates the data with factor of 2 for high availability.
The best way to identify reuse is to read and understand the SQL query execution plans or the DAG, the point in DAG where you see multiple arrows being carried to different stages/jobs. The DAG's don't lie! Also don't forget to write an unpersist() method for every persist or cache method post usage of data.
RDD vs. DataFrame vs. DataSet
1. RDD -
- RDD's works best in cases where data is very unstructured and still we need to process that data using some or other compute.
- All the computations done on RDD are opaque and Data is also opaque. By Opaque I mean spark does not have a good understanding of the data which makes it hard to self-optimise computations for performance improvements
- The best and worst part about working with RDD's is actually the low level APIs exposed by Spark RDD. Good because it offers a great control and flexibility which enables developers to manipulate data in all possible ways. And Bad because the API's are a bit difficult compared to Dataframe/Dataset APIs also leaves out great scope for errors.
2. DataFrames/DataSets -
- DataFrames post spark 2 are nothing but DataSet[Row].
- Both of them have unified high level APIs, which makes it very easy for understanding and developing clean Spark Applications.
- Unlike RDD's they provide strong type-safety
- The best part about using DFs/DS is the ability to make use of Catalyst Optimiser, Tungsten 2 and Whole stage CodeGen. Find more about them here. Tungsten, Catalyst Optimiser, Whole Stage Code Generator
- The above means Spark exactly knows the Data, the Computations and the possible Optimisations for your Application.
The Final Comparison in terms of performance numbers -

(source: Databricks)
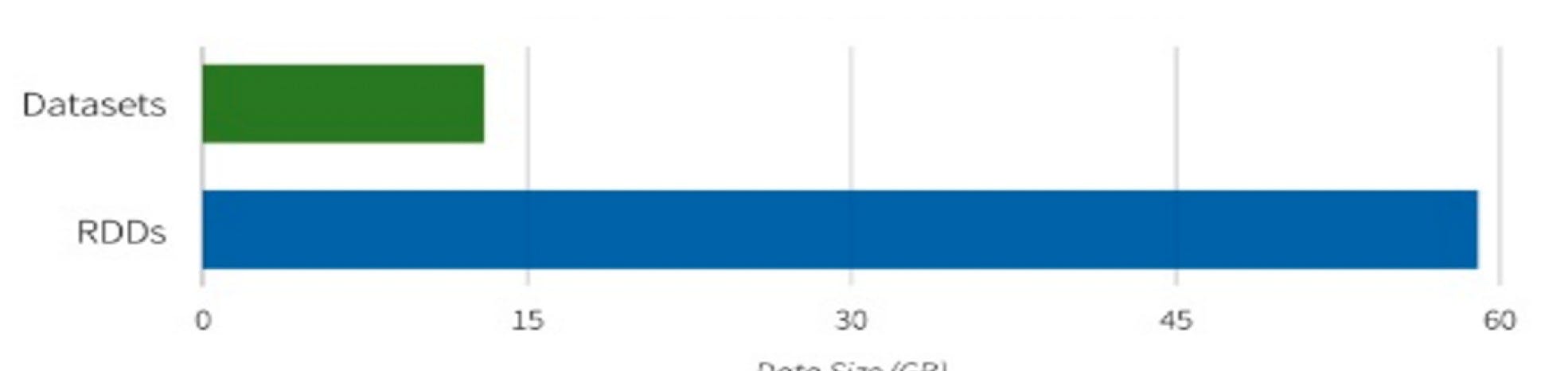
Memory usage while caching
Other Optimisations
We have now reached at the end of today's post but before I sign off, let me call out the honourable mentions while optimising spark applications in easy bullet points.
- make use of broadcast joins if you are joining a smaller table with a larger one.
- Identify skew in data, skew is still the top most reason for bad performing jobs.
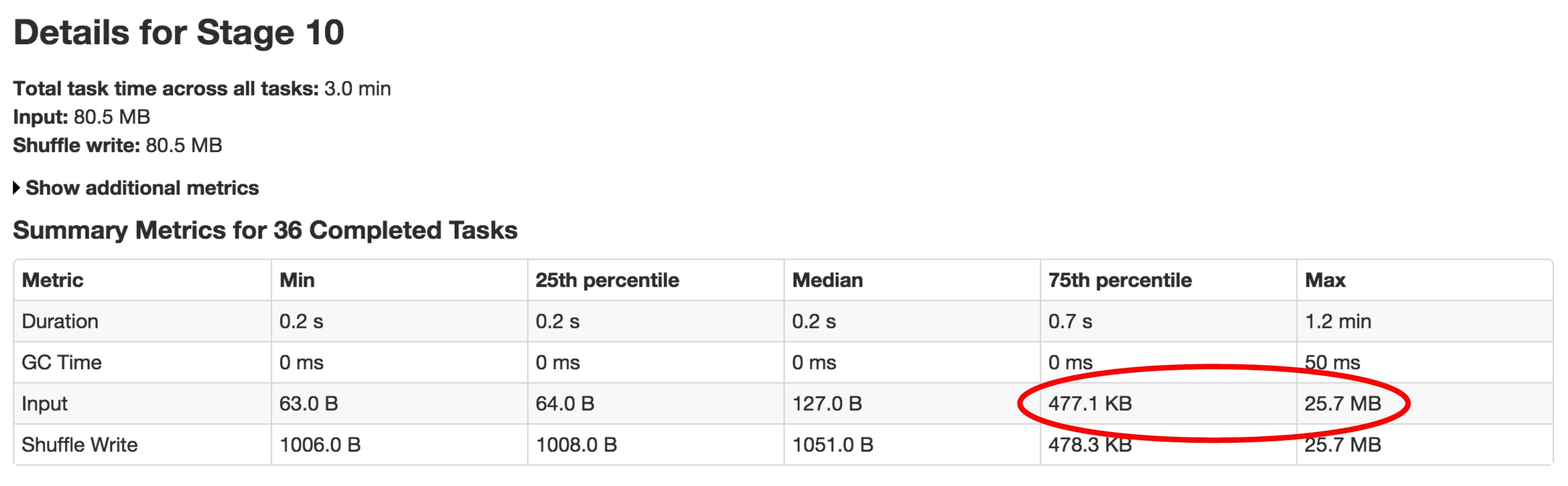 If we see the above marked section closely, that is how you identify skews in your data. this is simply because one or two keys/partitions have huge number of rows and delays up the entire application while computing a single partition. Use salting to get rid of skews.
If we see the above marked section closely, that is how you identify skews in your data. this is simply because one or two keys/partitions have huge number of rows and delays up the entire application while computing a single partition. Use salting to get rid of skews.
- Avoid using df.show or df.count in production applications, check if you REALLY need it? If it's very important and you can't do without it try using accumulators, or try using
ApproxCountDistinctfor that matter. - Use distinct/ dropDuplicates wisely, if at all you need them. If you need it anyway try to use them before join or group by operation to reduce keys before heavy compute.
- One Fat Spark Application to do everything can affect performance see if you can split that into multiple smaller applications. that way you will reduce the amount of time spent in GC.
- Make use of columnar data storage options wherever possible. [ Spark <3 Parquet ]
- Use Kryo serialisation.
- Avoid collect operations on larger RDDs
- Enable Speculative execution and tune following parameters spark.speculation.interval - check for tasks to speculate. spark.speculation.multiplier - How many times slower a task than median spark.speculation.quantile - Fraction of tasks completed in a stage before
- Optimise, Optimise and Optimise.
I have shared enough about spark application performance tuning, I hope this is helpful. This is the third blog in the Spark Performance Tuning series, In future I'll try to add couple more posts along the same lines.
Until then, Keep Learning and Keep Optimising!