Each node that stores a copy of the database is called a replica
Every write to the database needs to be processed by every replica; otherwise, the replicas would no longer contain the same data, common solution is master–slave replication
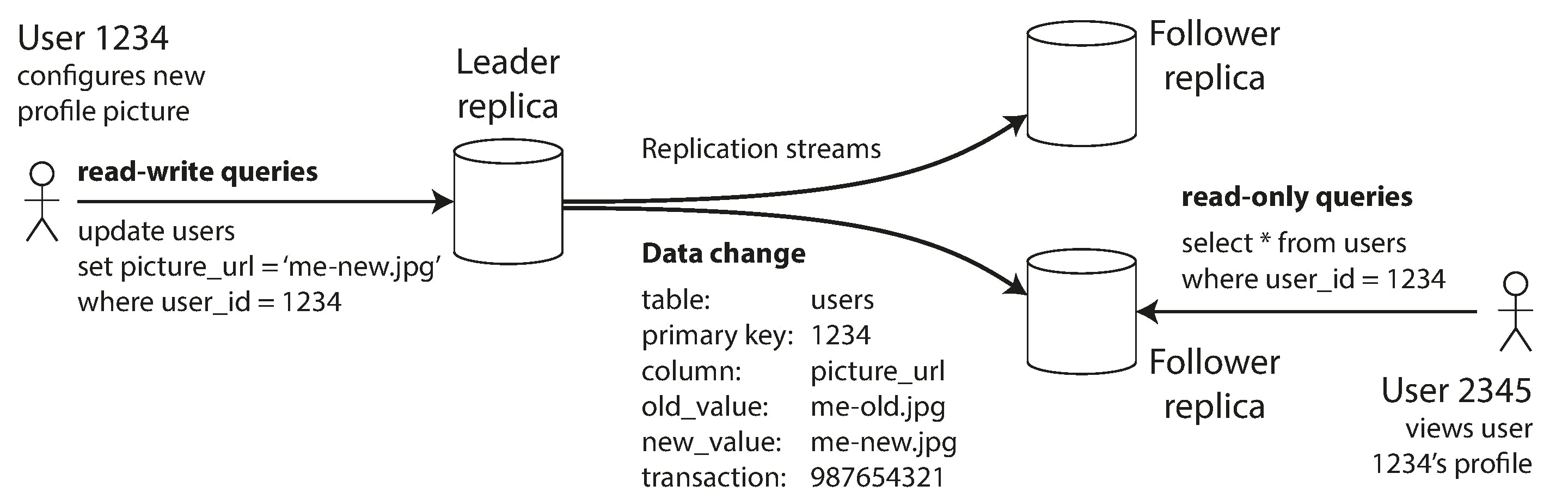
One of the replicas is designated the leader (also known as master or primary
All writes to the database, must send their requests to the leader
The other replicas are known as followers (read replicas, slaves, secondaries, or hot standbys).
Whenever the leader writes new data to its local storage, it also sends the data change to all of its followers as part of a replication log or change stream
Each follower takes the log from the leader and updates its local copy of the database accordingly
When a client wants to read from the database, it can query either the leader or any of the followers. However, writes are only accepted on the leader
Synchronous Versus Asynchronous Replication
The advantage of synchronous replication is that the follower is guaranteed to have an up-to-date copy of the data that is consistent with the leader.
The disadvantage is that if the synchronous follower doesn’t respond, the write cannot be processed
asynchronous configuration has the advantage that the leader can continue processing writes
Weakening durability may sound like a bad trade-off, but asynchronous replication is nevertheless widely used, especially if there are many followers or if they are geographically distributed.
How do you achieve high availability with leader-based replication?
Follower failure: Catch-up recovery - On its local disk, each follower keeps a log of the data changes it has received from the leader.
the follower can recover quite easily: from its log, it knows the last transaction that was processed before the fault occurred.
Leader failure: Failover - Handling a failure of the leader is trickier: one of the followers needs to be promoted to be the new leader
clients need to be reconfigured to send their writes to the new leader, and the other followers need to start consuming data changes from the new leader. This process is called failover.
Determining that the leader has failed - nodes frequently bounce messages back and forth between each other, and if a node doesn’t respond for some period of time, it is assumed to be dead
Choosing a new leader - This could be done through an election process where
the leader is chosen by a majority of the remaining replicas.
Reconfiguring the system to use the new leader - Clients now need to send their write requests to the new leader