why we distribute a database across multiple machines
Scalability - data volume, read/write load grows more than what a single machine can handle
Fault Tolerance/ HA - we want application/db to continue operating even if a node/network/datacenter goes down.
Latency - Avoid wait time for user requests to travel halfway around the world for results.
Shared-Memory Architecture or Scaling Vertically or Scaling up
Many CPUs, many RAM chips, and many disks can be joined together under one operating system, and a fast interconnect allows any CPU to access any part of the memory or disk.
Problems with shared memory architecture,
the cost grows faster than linearly
a machine twice the size cannot necessarily handle twice the load
limited fault tolerance
limited to a single geographic location.
Shared-Nothing Architectures or Scaling Horizontally or Scaling Out
In this approach, each machine or virtual machine running the database software is called a node. Each node uses its CPUs, RAM, and disks independently.
Coordination between nodes is done at the software level, using a conventional network.
you can use whatever machines have the best price/performance ratio.
distribute data across multiple geographic regions, and thus reduce latency for users, also might be able to survive loss of a datacenter.
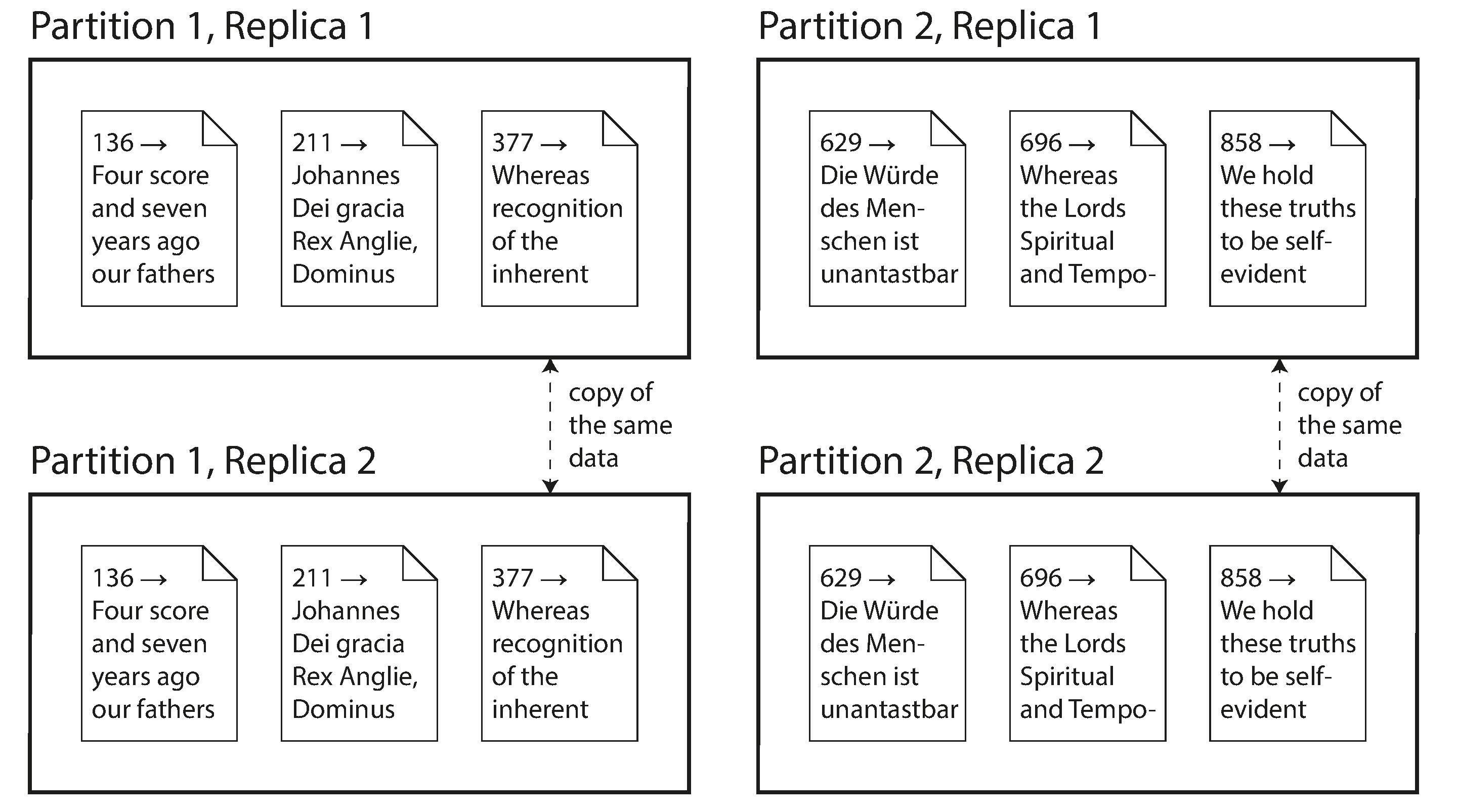
Replication vs Partitioning
Replication
keeping a copy of the same data on multiple machines that are connected via a network
Why we might do it,
To keep data geographically close to your users (and thus reduce latency)
To allow the system to continue working even if some of its parts have failed
(and thus increase availability)
To scale out the number of machines that can serve read queries (and thus
increase read throughput)
The main challenge of replication is handling the changes to replicated data