

Designing Data-Intensive Applications [Book Highlights]
[Part I : Chapter IV] Encoding and Evolution
Avro
- Avro uses a schema to specify the structure of the data being encoded.
- It has two schema languages:
- one (Avro IDL) intended for human editing
record Person { string userName; union { null, long } favoriteNumber = null; array<string> interests; } - one based on JSON that is more easily machine-readable
{ "type": "record", "name": "Person", "fields": [ {"name": "userName", "type": "string"}, {"name": "favoriteNumber", "type": ["null", "long"], "default": null}, {"name": "interests", "type": {"type": "array", "items": "string"}} ] }
- one (Avro IDL) intended for human editing
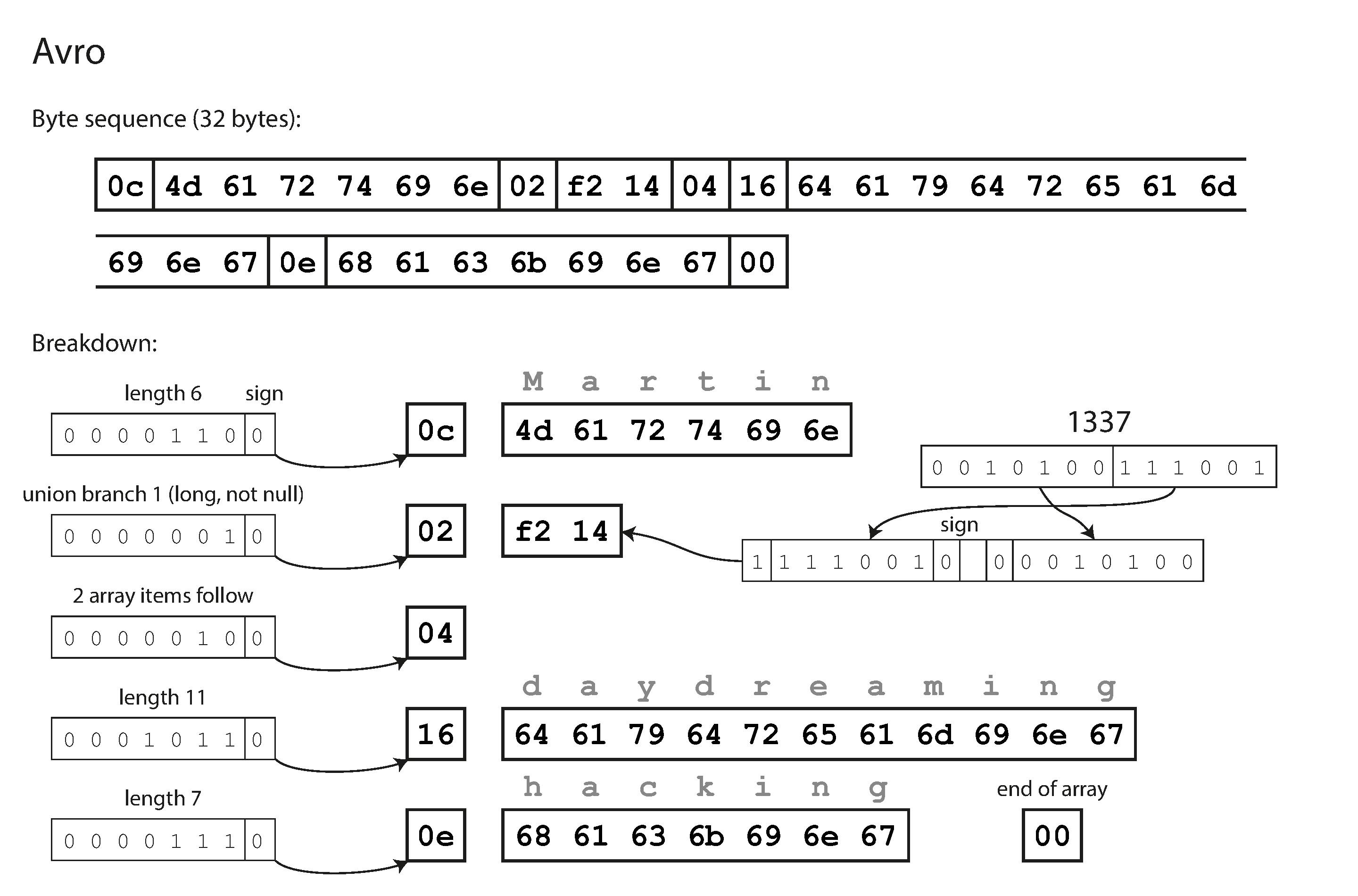
- If we encode our example record using this schema, the Avro binary encoding is just 32 bytes long [compact of all]
- When an application wants to encode/write data it uses the schema which was compiled with the code, that schema is called writer's schema
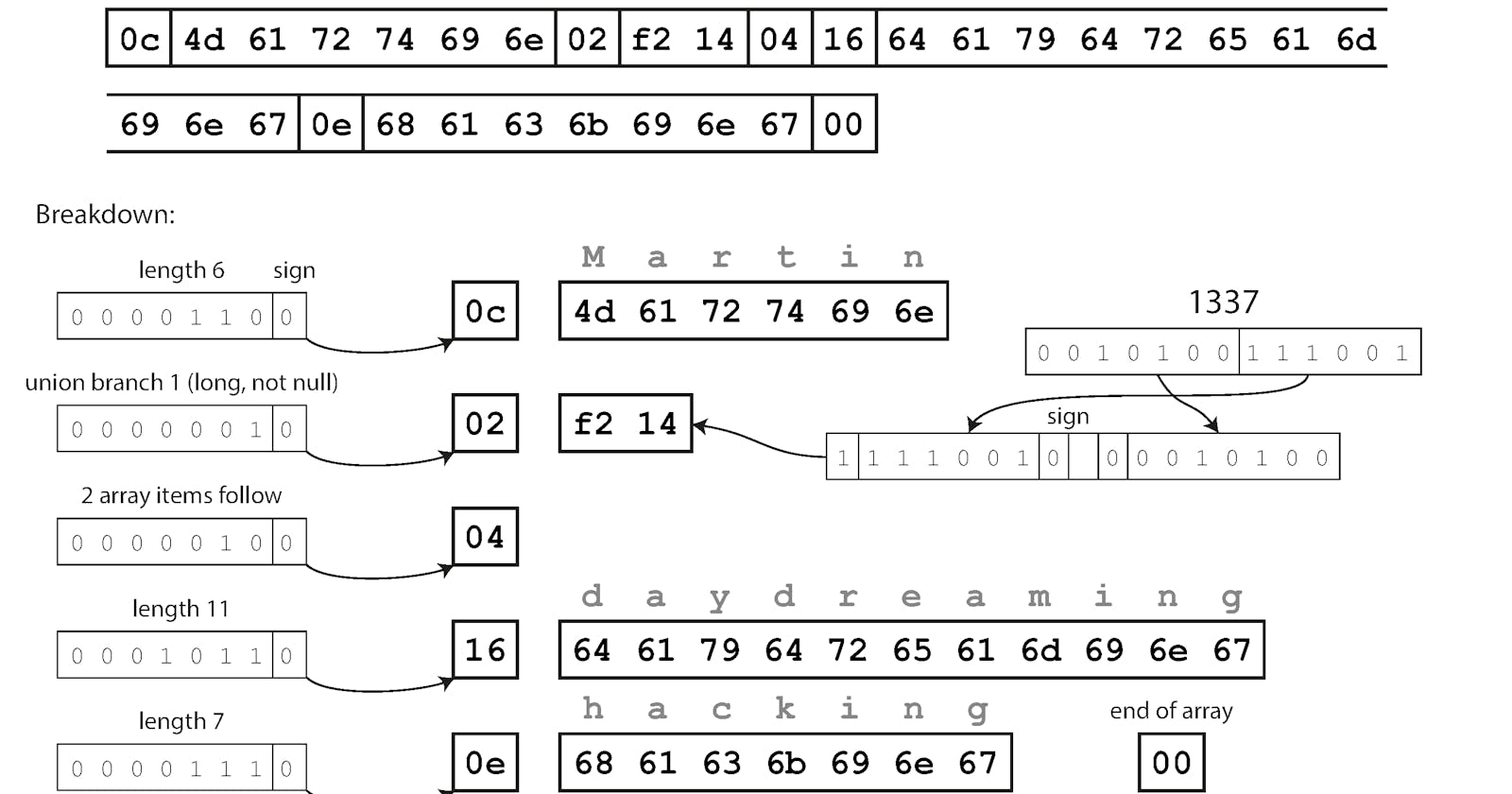
- When an application wants to decode/read data it is expecting data to be in some schema, which is called as reader's schema
- The key idea with Avro is that the writer’s schema and the reader’s schema don’t have to be the same—they only need to be compatible.
- Avro library resolves the differences by looking at the writer’s schema and the reader’s schema side by side
- reader's schema and writer's schema diff
- fields in a different order is acceptable as schema resolution matches up the fields by field name
- a field that appears in the writer’s schema but not in the reader’s schema, it is ignored
- expects some field, but the writer’s schema does not contain a field of that name, it is filled in with a default value declared in the reader’s schema.