



Designing Data-Intensive Applications [Book Highlights]
[Part I : Chapter III] Storage and Retrieval
fundamentals of a database are two things: it should store the data, it should give it back as well.
Consider the world’s simplest database, implemented as two Bash functions:
#!/bin/bash
db_set () {
echo "$1,$2" >> database
}
db_get () {
grep "^$1," database | sed -e "s/^$1,//" | tail -n 1
}
- This is how it works
$ db_set 123456 '{"name":"London","attractions":["Big Ben","London Eye"]}'
$ db_set 42 '{"name":"San Francisco","attractions":["Golden Gate Bridge"]}'
$ db_get 42
{"name":"San Francisco","attractions":["Golden Gate Bridge"]}
- what db_set does, many databases internally use a log, which is an append-only data file.
- A Log is nothing but, an append-only sequence of records. It doesn’t have to be human-readable; it might be binary and intended only for other programs to read.
- db_get has to scan the entire database file from beginning to end, looking for occurrences of the key. In algorithmic terms, the cost of a lookup is O(n):
- if you double the number of records n in your database, a lookup takes twice as long. That’s not good.
- An index is an additional structure that is derived from the primary data
- Many databases allow you to add and remove indexes, and this doesn’t affect the contents of the database; it only affects the performance of queries.
- Any kind of index usually slows down writes, because the index also needs to be updated every time data is written.
- well-chosen indexes speed up read queries, but every index slows down writes.
Hash Indexes
- Let’s say our data storage consists only of appending to a file
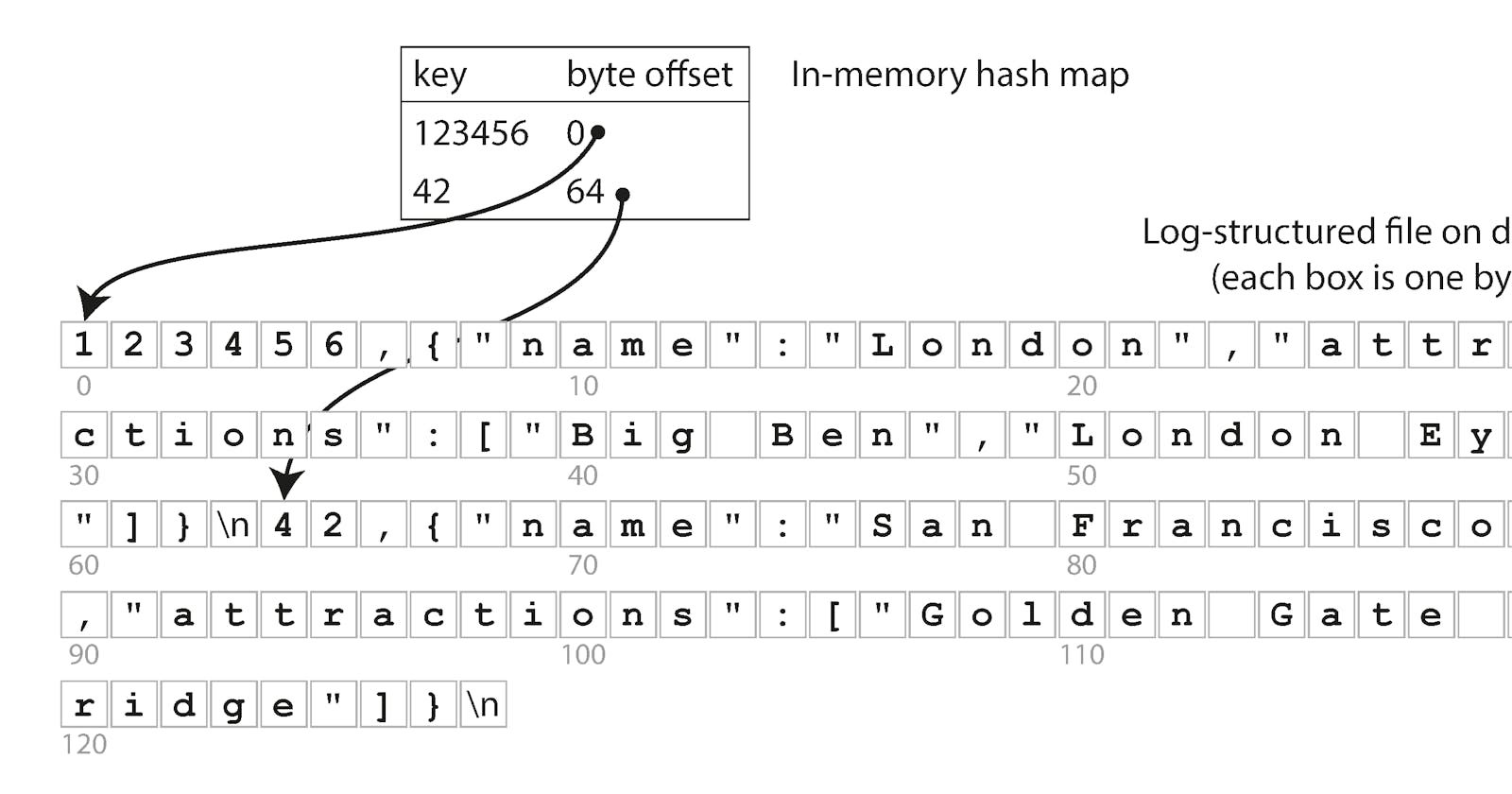
- Then the simplest possible indexing strategy is this: keep an in-memory hash map where every key is mapped to a byte offset in the data file—the location at which the value can be found.
 Storing a log of key-value pairs in a CSV-like format, indexed with an in-memory hashmap.
Storing a log of key-value pairs in a CSV-like format, indexed with an in-memory hashmap.
- This approach is useful in workloads where there are a lot of writes, but there are not too many distinct keys—you have a large number of writes per key, but it’s feasible to keep all keys in memory.
- In this approach, we only ever append to a file.
- to avoid eventually running out of space, it is good to break the log into segments of certain size.
- We can then perform compaction on these segments, as illustrated in below image
 Compaction of a key-value update log (counting the number of times each cat video was played), retaining only the most recent value for each key.
Compaction of a key-value update log (counting the number of times each cat video was played), retaining only the most recent value for each key.
- The merging and compaction of frozen segments can be done in a background thread, and while it is going on, we can still continue to serve read and write requests as normal, using the old segment files.
- File format - CSV is not the best format for a log. It’s faster and simpler to use a binary format that first encodes the length of a string in bytes, followed by the raw string (without need for escaping).
- Deleting records - If you want to delete a key and its associated value, you have to append a special deletion record to the data file (sometimes called a tombstone). When log segments are merged, the tombstone tells the merging process to discard any previous values for the deleted key.
- Crash recovery - If the database is restarted, the in-memory hash maps are lost. In principle, you can restore each segment’s hash map by reading the entire segment file
- Partially written records - The database may crash at any time, including halfway through appending a record to the log. Bitcask files include checksums, allowing such corrupted parts of the log to be detected and ignored.
Concurrency control - As writes are appended to the log in a strictly sequential order, a common implementation choice is to have only one writer thread. Data file segments are append-only and otherwise immutable, so they can be read concurrently by multiple threads.
Advantages
- Appending and segment merging are sequential write operations, which are generally much faster than random writes,
- Concurrency and crash recovery are much simpler if segment files are appendonly or immutable.
- Merging old segments avoids the problem of data files getting fragmented over time.
Drawbacks
- The hash table must fit in memory, so if you have a very large number of keys, you’re out of luck.
- Range queries are not efficient. For example, you cannot easily scan over all keys between kitty00000 and kitty99999—you’d have to look up each key individually in the hash maps.