



Designing Data-Intensive Applications [Book Highlights]
[Part I : Chapter IV] Encoding and Evolution
- Apache Thrift and Protocol Buffers (protobuf) are binary encoding libraries that are based on the same principle
- Both Thrift and Protocol Buffers require a schema for any data that is encoded.
- To encode the data in
- Thrift
struct Person { 1: required string userName, 2: optional i64 favoriteNumber, 3: optional list<string> interests } - Protocol Buffers
message Person { required string user_name = 1; optional int64 favorite_number = 2; repeated string interests = 3; }
- Thrift
- Thrift and Protocol Buffers each come with a code generation tool that takes a schema definition like the ones shown here, and produces classes that implement the schema in various programming languages
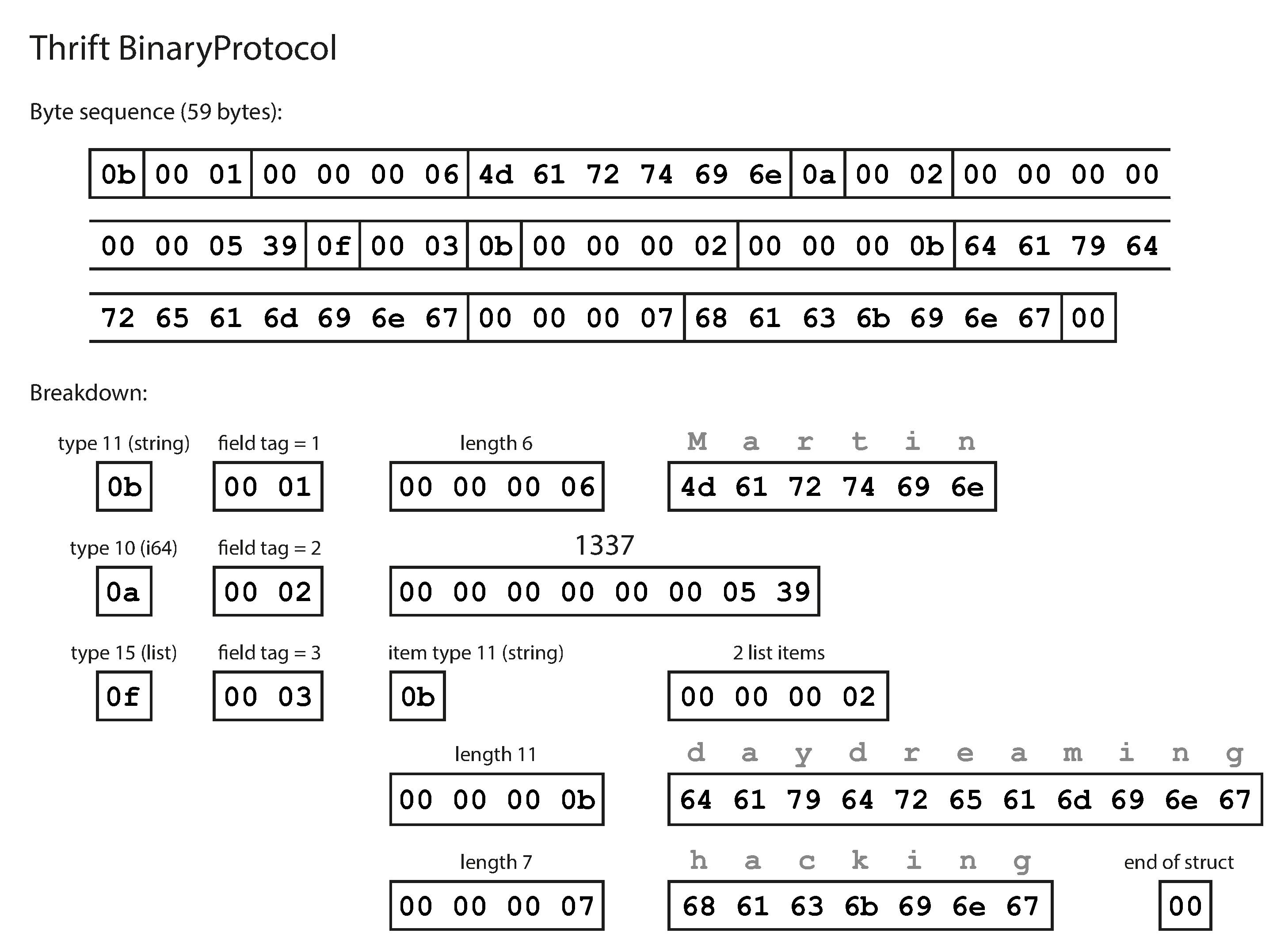
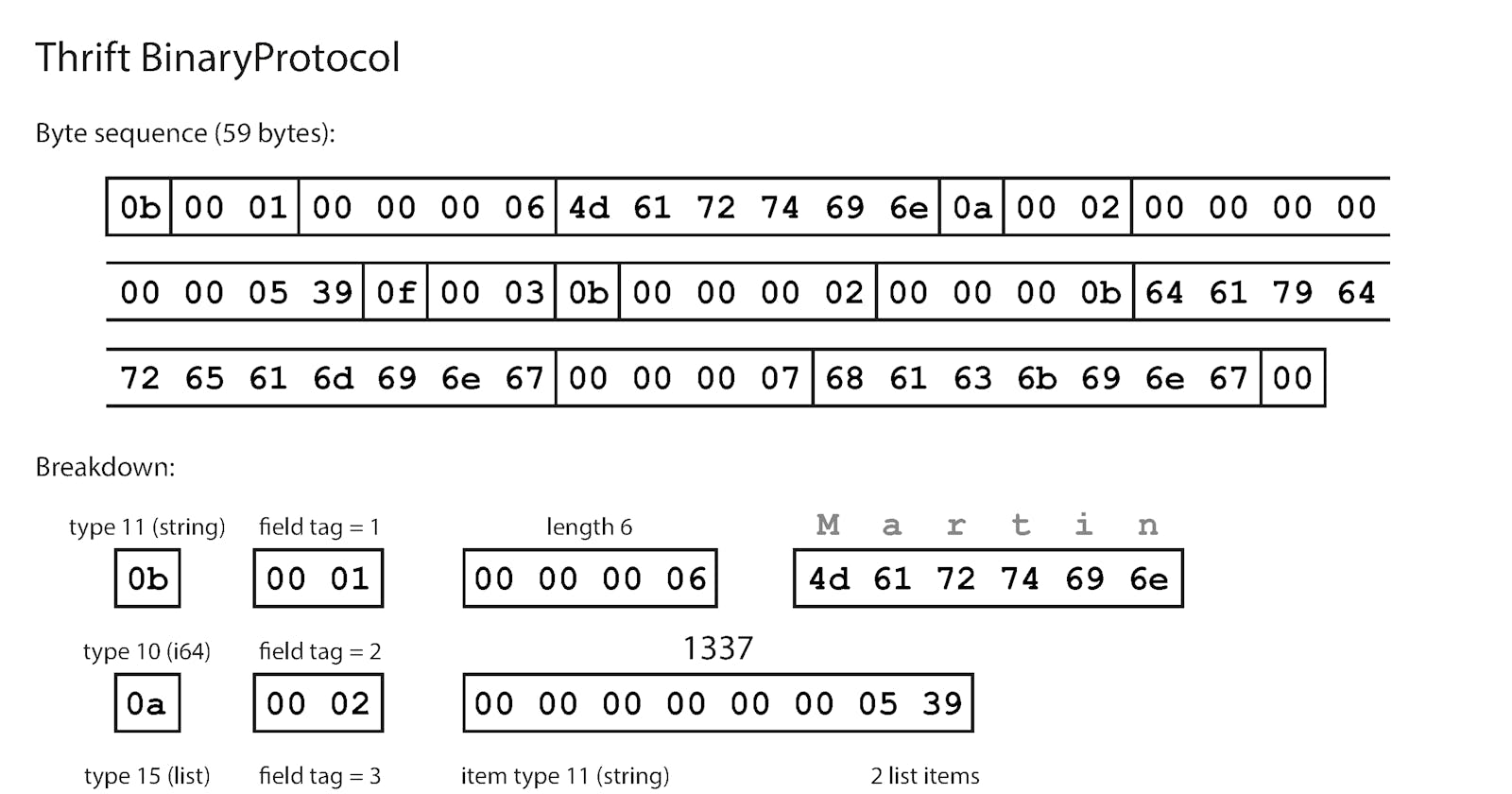
BinaryProtocol - each field has a type annotation and, where required, a length indication. The strings that appear in the data (“Martin”, “daydreaming”, “hacking”) are also encoded as ASCII but there are no field names Instead, the encoded data contains field tags. It takes 59Bytes to store the above information.
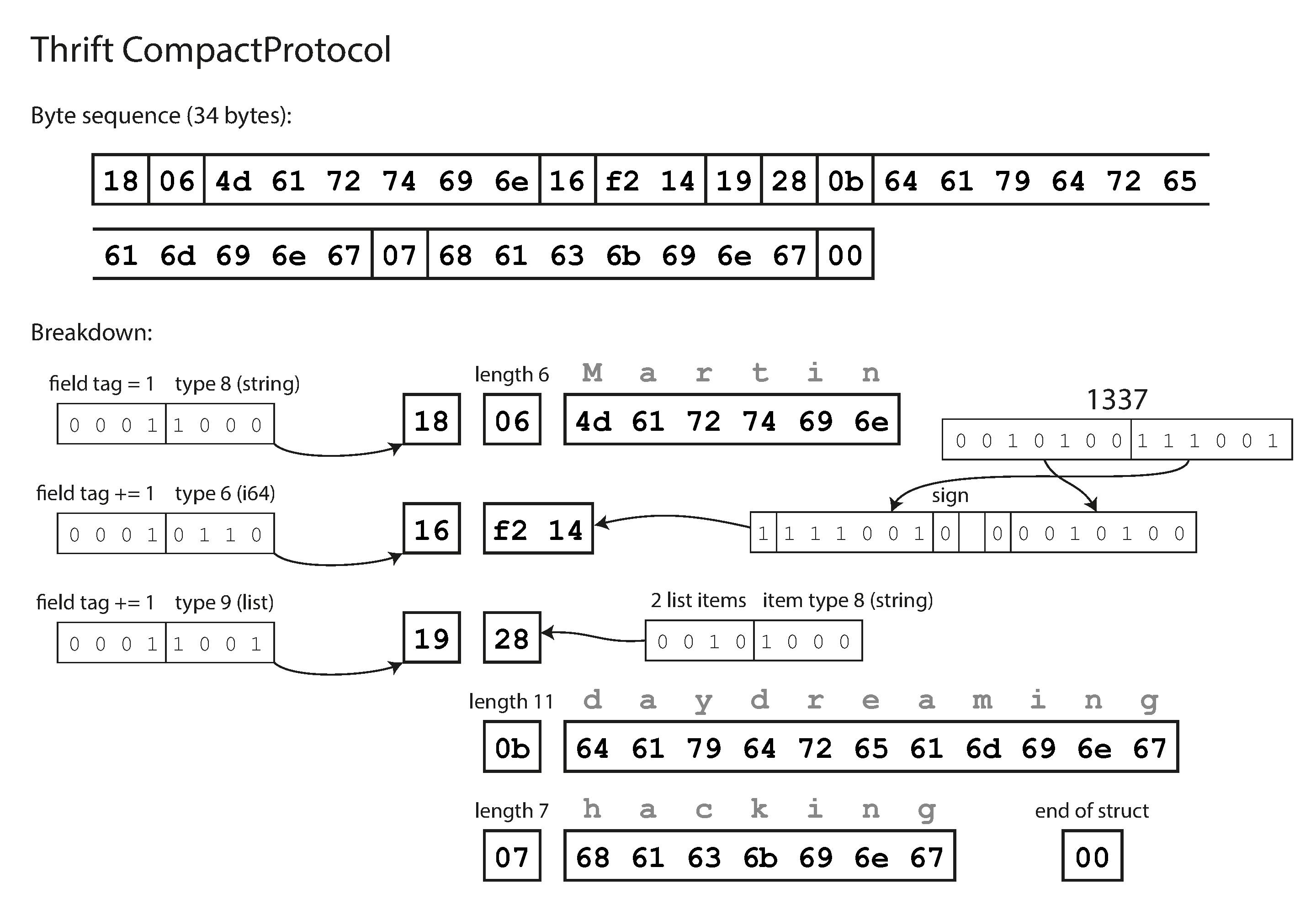
CompactProtocol - it packs the same information into only 34 bytes, packs the field type and tag number into a single byte. uses variable-length integers. Rather than using a full eight bytes for the number 1337, it is encoded in two bytes, with the top bit of each byte used to indicate whether there are still more bytes to come. This means numbers between –64 and 63 are encoded in one byte, numbers between –8192 and 8191 are encoded in two bytes, etc.
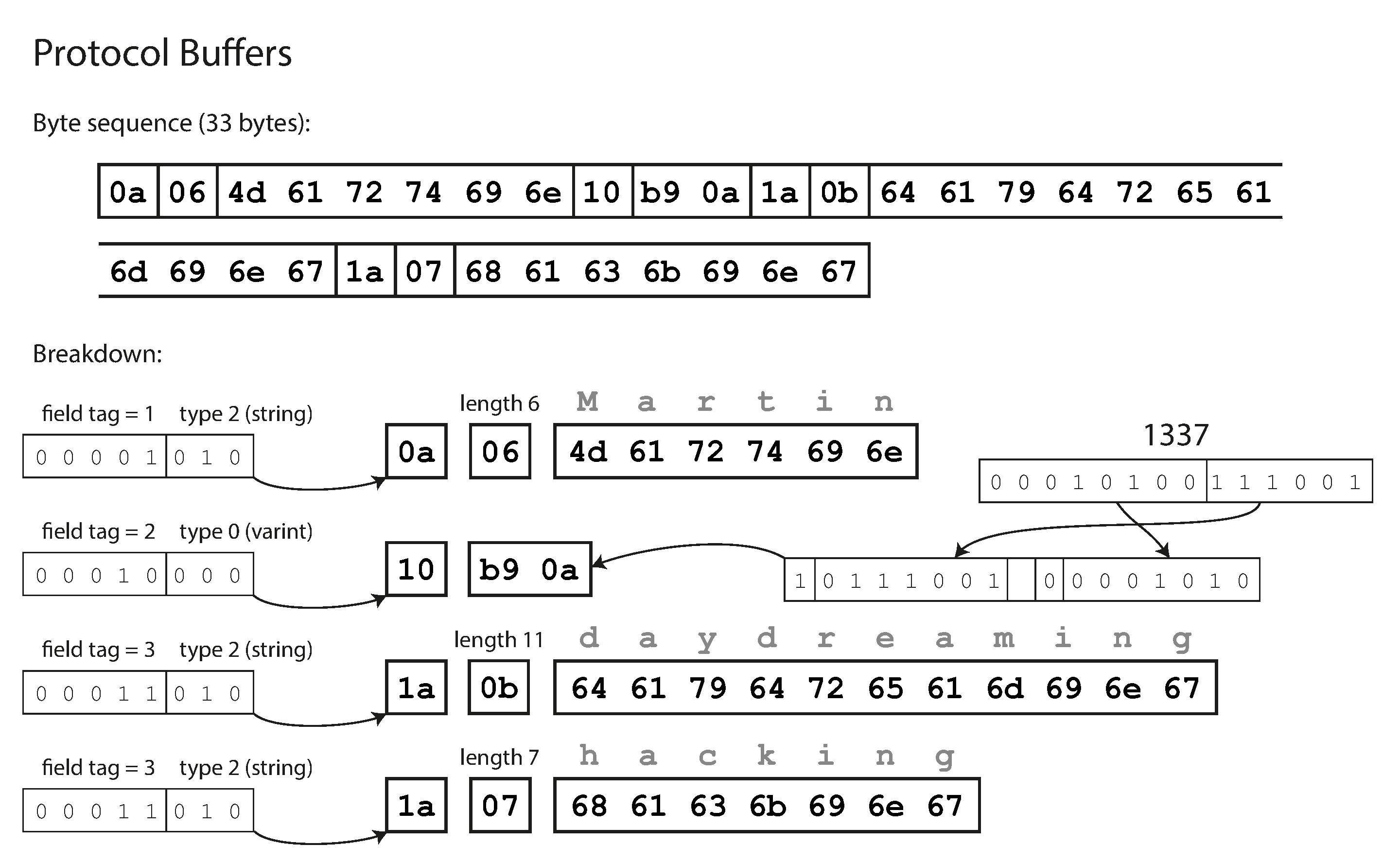
- Protocol Buffers - It does the bit packing slightly differently, fits the same record in 33 bytes. each field was marked either required or optional, but this makes no difference to how the field is encoded.
schema evolution
- Each field is identified by its tag number, we can change the field name as it refers to the schema and the tag number remains same.
- If a field value is not set, it is simply omitted from the encoded record
- You can add new fields to the schema, provided that you give each field a new tag number.
- If old code tries to read data written by new code, including a new field with a tag number it doesn’t recognize, it can simply ignore that field. The datatype annotation allows the parser to determine how many bytes it needs to skip
- backward compatibility, As long as each field has a unique tag number, new code can always read old data
- to maintain backward compatibility, every field you add after the initial deployment of the schema must be optional or have a default value.
- Removing a field is just like adding a field, with backward and forward compatibility concerns reversed.
- changing the datatype of a field is possible but there is a risk that values will lose precision or get truncated