



Designing Data-Intensive Applications [Book Highlights]
[Part I : Chapter III] Storage and Retrieval
B-Trees
- The most widely used indexing structure is the B-tree.
- B-trees keep key-value pairs sorted by key, which allows efficient keyvalue lookups and range queries
- B-trees break the database down into fixed-size blocks or pages, traditionally 4 KB in size (sometimes bigger), and read or write one page at a time
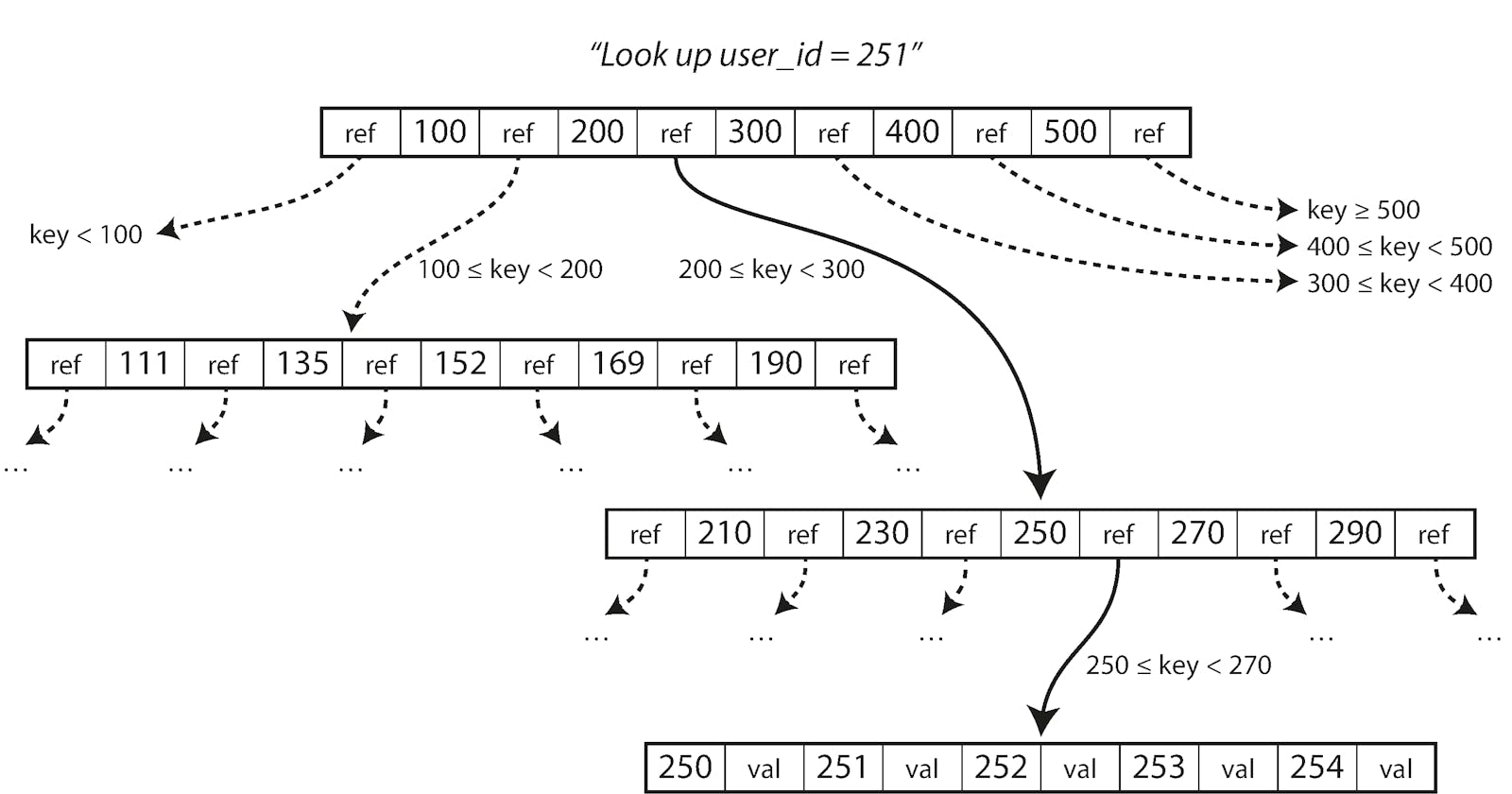
 Looking up a key using a B-tree index.
Looking up a key using a B-tree index.
- a B-tree with n keys always has a depth of O(log n)
- A four-level tree of 4 KB pages with a branching factor of 500 can store up to 256 TB.
- a write-ahead log (WAL, also known as a redo log) is an append-only file to which every B-tree modification must be written before it can be applied to the pages of the tree itself
Optimisations
- We can save space in pages by not storing the entire key, but abbreviating it.
- Many Btree implementations therefore try to lay out the tree so that leaf pages appear in sequential order on disk.
- Additional pointers have been added to the tree. For example, each leaf page may have references to its sibling pages to the left and right, which allows scanning keys in order without jumping back to parent pages.
- B-tree variants such as fractal trees borrow some log-structured ideas to reduce disk seeks
- LSM-trees are typically faster for writes, whereas B-trees are thought to be faster for reads
- A B-tree index must write every piece of data at least twice: once to the write-ahead log, and once to the tree page itself
- LSM-trees can be compressed better, and thus often produce smaller files on disk than B-trees.
- LSM trees compaction process can sometimes interfere with the performance of ongoing reads and writes.
- the response time of queries to log-structured storage engines can sometimes be quite high, and B-trees can be more predictable
- An advantage of B-trees is that each key exists in exactly one place in the index, whereas a log-structured storage engine may have multiple copies of the same key in different segments
Other Indexing Structures
- A secondary index can easily be constructed from a key-value index. The main difference is that keys are not unique.
- The most common type of multi-column index is called a concatenated index, which simply combines several fields into one key by appending one column to another
- An interesting idea is for multi-dimensional indexes would be an ecommerce website using a three-dimensional index on the dimensions (red, green, blue) to search for products in a certain range of colors
- full-text search engines commonly allow a search for one word to be expanded to include synonyms of the word
- Many datasets are simply not that big, so it’s quite feasible to keep them entirely in memory, potentially distributed across several machines. This has led to the development of in-memory databases.
- When an in-memory database is restarted, it needs to reload its state, either from disk or over the network from a replica