



Designing Data-Intensive Applications [Book Highlights]
[Part I : Chapter II] Data Models and Query Languages
Query Languages for Data
- An imperative language tells the computer to perform certain operations in a certain order.
- In a declarative query language, like SQL, you just mention what conditions the data should meet and what transformations. but not how.
- A declarative query language is attractive, as it hides implementation details of engine, making the database system able to introduce performance improvements without requiring any changes to queries.
- Declarative languages have a better chance of getting faster in parallel execution because they specify only the pattern of the results, not the algorithm.
MapReduce Querying
- MapReduce is a programming model for processing large amounts of data in bulk across many machines, popularized by Google
- A limited form of MapReduce is supported by some NoSQL datastores, including MongoDB and CouchDB, as a mechanism for performing read-only queries across many documents.
- MapReduce is neither a declarative query language nor a fully imperative query API, but somewhere in between
- It is based on the map (also known as collect) and reduce (also known as fold or inject) functions
- A usability problem with MapReduce is that you have to write two carefully coordinated functions,
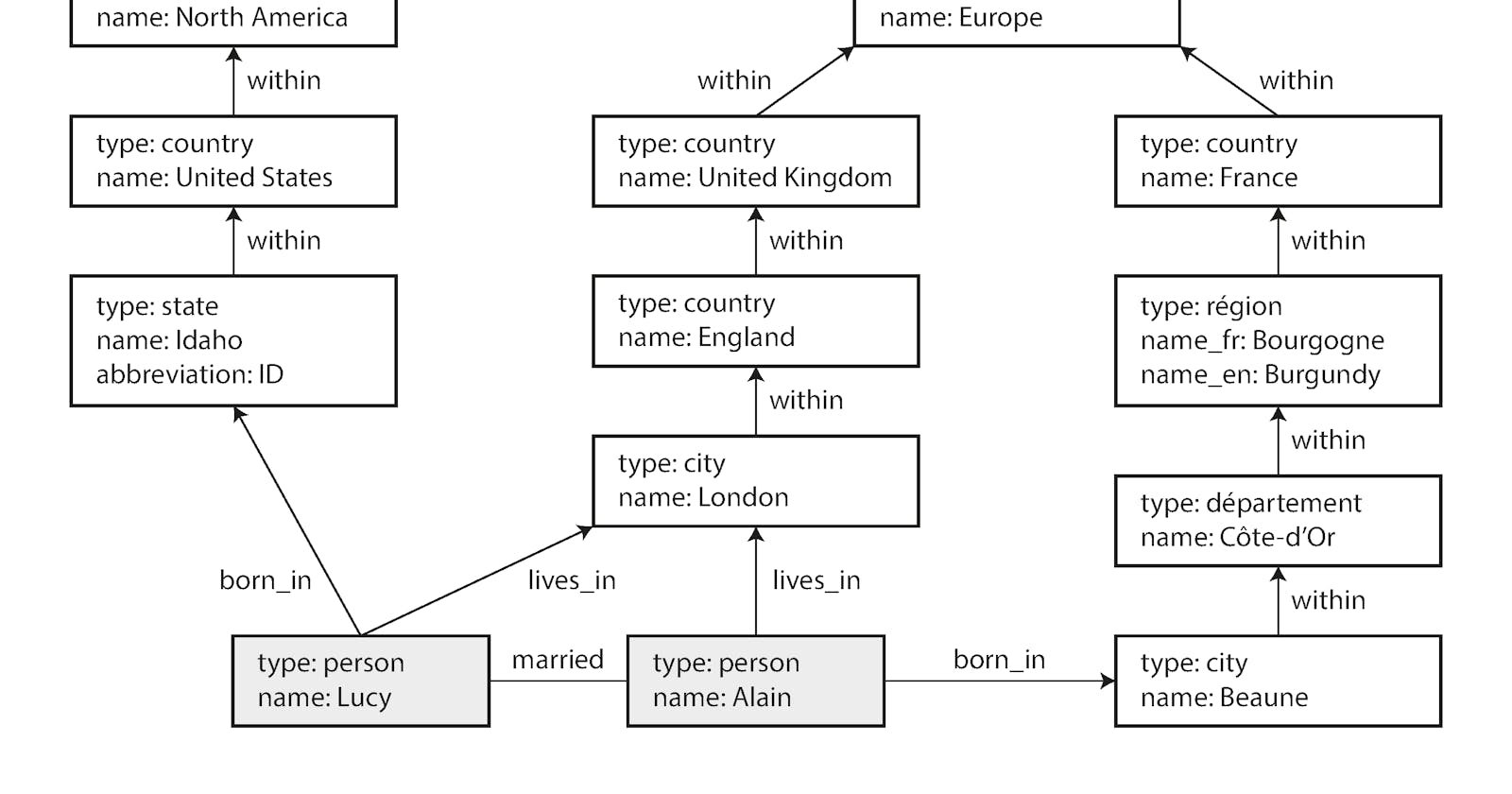
Graph-Like Data Models
- if many-to-many relationships are very common in your data, the connections within your data become more complex, it becomes more natural to start modeling your data as a graph.
 Example of graph-structured data (boxes represent vertices, arrows represent
edges).
Example of graph-structured data (boxes represent vertices, arrows represent
edges).
Property Graphs
- In the property graph model, each vertex consists of:
- A unique identifier
- A set of outgoing edges
- A set of incoming edges
- A collection of properties (key-value pairs)
Each edge consists of:
- A unique identifier
- The vertex at which the edge starts (the tail vertex)
- The vertex at which the edge ends (the head vertex)
- A label to describe the kind of relationship between the two vertices
- A collection of properties (key-value pairs)
Any vertex can have an edge connecting it with any other vertex. There is no schema that restricts which kinds of things can or cannot be associated.
- Given any vertex, you can efficiently find both its incoming and its outgoing edges, and thus traverse the graph
- By using different labels for different kinds of relationships, you can store several different kinds of information in a single graph