

Apache Spark Performance Tuning - Partitions
How partitioning can play a very powerful role in optimising spark jobs


Spark Overview
Apache documentations mentions spark framework something like this,
Apache Spark is a unified analytics engine for large-scale data processing. It provides high-level APIs in Java, Scala, Python and R, and an optimised engine that supports general execution graphs. It also supports a rich set of higher-level tools including Spark SQL for SQL and structured data processing, MLlib for machine learning, GraphX for graph processing, and Structured Streaming for incremental computation and stream processing.
I think it kind of summarises what this framework is capable doing. The performance benchmarks are out of the box compared to hadoop map-reduce framework (like 100X improvement while running Logistic regression or 10X improvement while sorting 100TB data)
But...
When a developer starts working with spark the on-boarding is easy and fast. It has high level APIs in multiple languages, and they are easy to use. The main problem starts when we go to production! And scaling a spark job can get really difficult in some cases.
So to eradicate the scaling problem we need to tune the spark jobs since it provide so many configuration options. In this specific blog we will focus on spark partition tunning.
Partition Tunning
Partitioning is a very powerful way to optimise spark jobs. If used correctly it can help,
- Avoid spills on disks
- Maximise parallelism between tasks
- Utilise all the available cores to its capacity
- Helps save cores/ resources
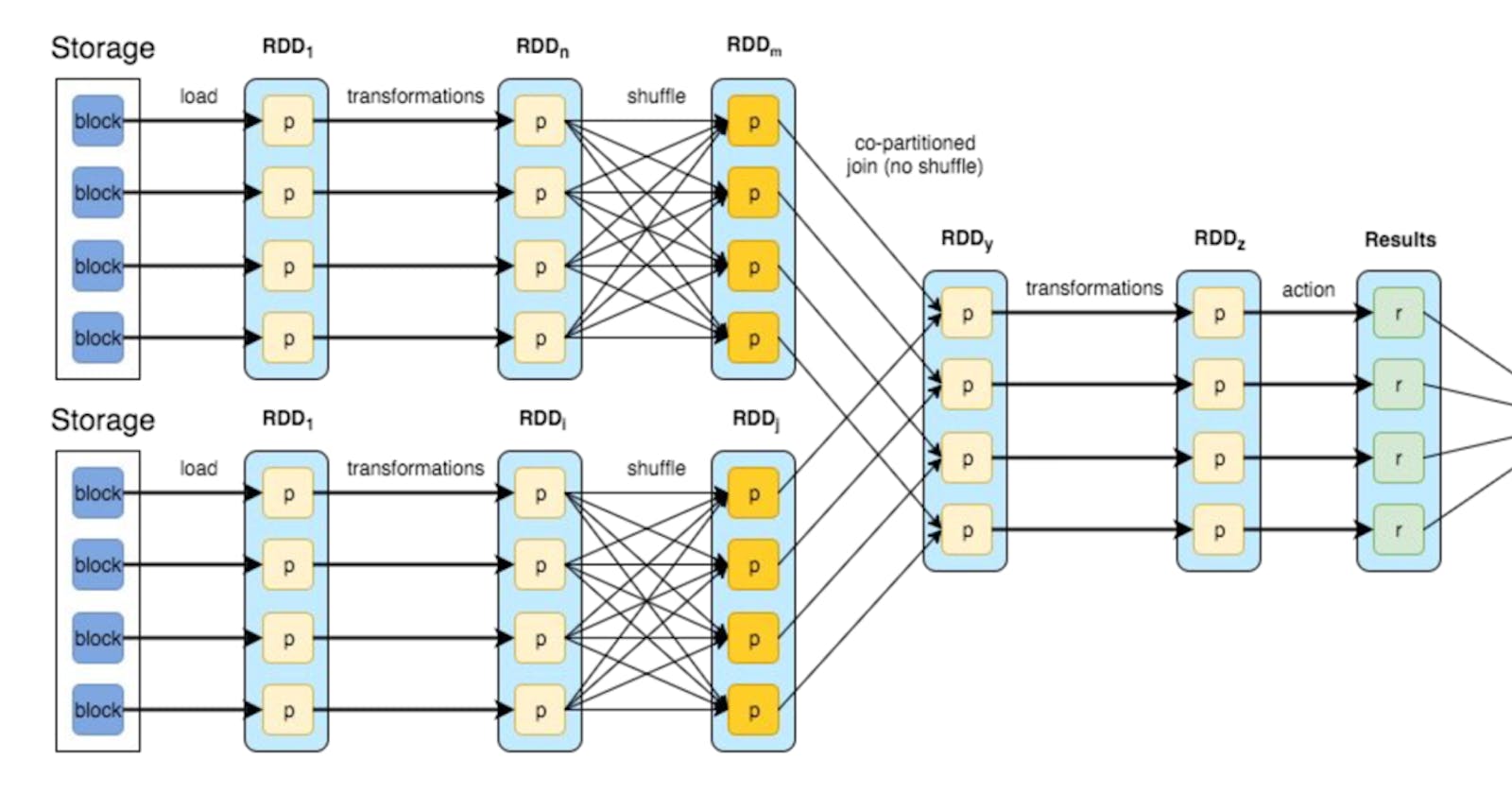
Spark jobs can be tunned for better performance at following three partitioning levels
Input Partitioning
If we tune Input partitions mainly it will control the size of data that each task would be have to deal with and that is really a good point to start.
Spark is very good at handling input partitioning by it self, most of the times you don't need to change anything here. Default input partition size is 128MB. To control and tune this partition use this spark config size spark.sql.files.maxPartitionBytes. That being said there would be scenarios like following where you would want to control it,
- Increase parallelism
Consider a case, You have written a wonderful spark job, you have lot of resources at your disposal, still your first stage of your job is slow and underutilising the given resources. In this case we can reduce the maxPartitionBytes to distribute the input data to multiple executors so that each task runs faster.
Example - Consider we have 200 cores available, and default maxPartitionBytes would make total 10 Input partitions for something like 1GB of data. In this case only 10 cores will be used and rest would be idle. Which I suppose is not very desirable!
- Nested data or Explode operation
In many cases, we deal with nested array data structure like when working with row based data stores such as JSON or Avro. The main issue when working with such nested data is when we try to process it. Suppose we are having 3 level nested data and we are going deep to traverse and process it, this will not only take time but also a good amount of compute memory. And that there is a problem each task would get 128MB of input data and when we go on processing this nested data that can cause OOMs or slow operations. same is the case when we try to explode such kind of data that multiplies data size and can lead to OOMs. In this case reduce maxPartitionBytes to accomodate the nested data processing.
Shuffle Partitions
You can easily control shuffle partitions using this configuration spark.sql.shuffle.partitions, this is defaulted to 200 in spark. So for most of the cases we need to tune this parameter to achieve optimum runtime and also would avoid unnecessary spills. Keep in mind the following points while tuning shuffle partitions,
- So there is a rough thumb rule which says keep each shuffle partition size less than 200MB.
- Number of shuffle partitions should not be less than cores available.
- Adjust
spark.sql.shuffle.partitionsnumber in nearest multiples of number of cores available to avoid spills and optimise passes to execute.
Example - Consider you have stage input size of around 64GB and number of cores available are 90. So in this case by default spark would keep shuffle partitions to be 200. i.e. 6400 MB / 200 parts = ~320 MB [Size of each partition]
To tune this out, we use our thumb rule and keep partition size less than 200, something like 100MB. then reverse calculating the number of shuffle partitions would yield, 6400 MB / 100 MB = ~640 parts. And we round it off to nearest multiples of cores i.e. 90. (90*7)= 630.
By keeping 630 parts would finish the stage in 7th pass rather leaving 10 parts for 8th pass.
Output Partitions
Output partitions controls the number of files written out as output of your entire spark job.
Honest Opinion - don’t try to change the number of output files, that might break your job and add one more extra stage to write.
Now that I have said it, let's move forward. If you need to change output partitions anyway, use a different compactor/partitioner job.
- Use coalesce function on output to reduce number of output files
- Use repartition function to increase number of output files
- Never use repartition to reduce number of files. Try to avoid using repartitions altogether, if you can!
If you want to control number of records/rows in each of the output files use following function,
df.write.option(“ maxRecordsPerFile ”, n) where n is number of records per output file.
These were few of the ways by which you can optimise your spark jobs performance. This is first blog of Spark Performance Tuning series, I guess I might have few more blogs in the same series.
Until then, Keep Learning and Keep Optimising!